Simulation for Sensorimotor Control
Use Reinforcement Learning method to demonstrate human Center Nervous System's adaptability
Introduction
This is my first reinforcement learning project, and it is a theoretical tabular reinforcement learning method based project. In this project, I applied a reinforcement learning algorithm, Value-Iteration based Adaptive Dynamic Programming (ADP) to a augmented sensorimotor system to explain the Central Nervous System’s (CNS’s) learning ability and adaptivity to perturbed environment and time delay in limbs’ movement.
Method
The methodology is based on a previous research which models limb’s movement as a Linear Time-Invariant (LTI) system and applies Policy-Iteration based Adaptive Dynamic Programming (ADP) to a solve the unknown system dynamic. However, it did not take into account the time delay issues and CNS’s adaptability to time delay in sensorimotor control. To address this limitation, in this research, I introduced time delay to the LTI system and applied state-augmentation and Value Iteration based ADP algorithm to demonstrate the Central Nervous System’s (CNS’s) adaptability to time delay in limbs’ movement.
Modeling
The following is the how we model this scenario and how to introduce time delay. The experient scenario:
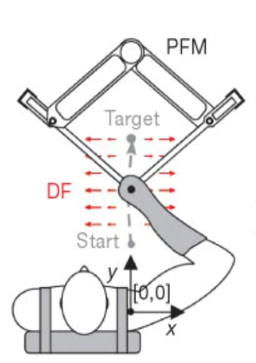
The system ordinary differential equations:
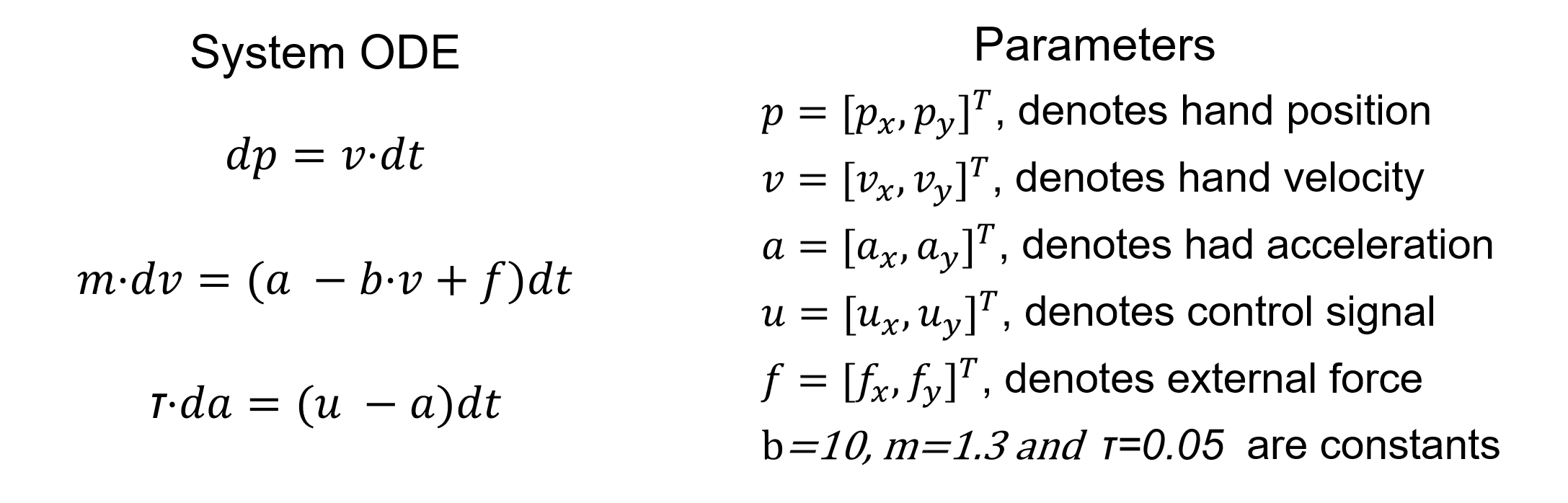
Introduce time delay to the system:

Augmentation
Inspired by a paper for autonomous vehicles and its state augmentation idea I augmented the state vector with past state and control vectors to eliminate the effect of time delay. To augment the system with past states and control vectors, we must first discretize the system. The discretization method is:

Then, augment the discrete LTI system with past state and control vectors:

Subsequently, I applied Value Iteration based ADP algorithm to the augmented LTI system and conducted simulation in a Python environment. The Value Iteration based ADP algorithm is shown as below. The Value Iteration based ADP is based on Value Iteration algorithm in Dynamic Programming when the system dynamic is known (model-based). Here is the model-based method is shown as below:
.png)
.png)
Adaptive Dynamic Programming
To solve the unknow system dynamic (Matrices A and B), we introduced the Data-Driven method, Value Iteration based ADP to generate the control gain matrix K (policy) from data obtained from the environment instead of the known system dynamic (Matrices A and B). (In some sense, this approach is similar to Q-learning, where H matrix defines the action-value function:)
.png)
.png)
.png)
.png)
By applying ADP, we can obtain the control policy from data instead of system model:
.png)
The overall algorithm is:
.png)
Results
The simluation result has shown CNS’s learning ability and adaptivity to perturbed environment and time delay in limbs’ movement. Human’s trajectory during learning:

Human’s trajectory after learning:

Model’s trajectory during learning:
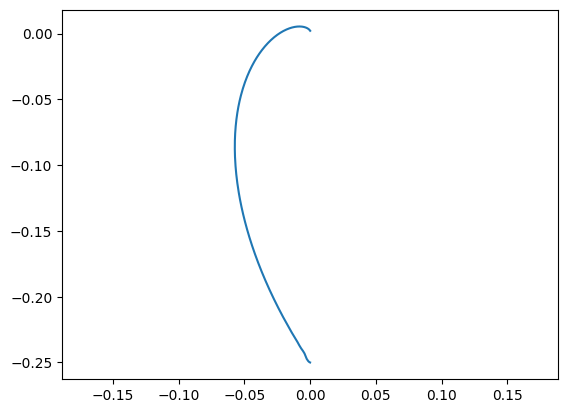
Model’s trajectory after learning:
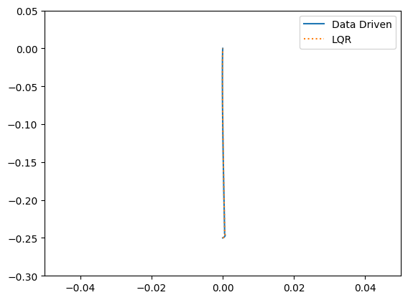
The project is implemented in Python and has not yet been uploaded to GitHub. For access to the project code, please feel free to contact me directly.